A Computer-Assisted System for Language Translation
Language translation systems based on neural networks have achieved impressive levels of performance. For everyday texts, their results are almost indistinguishable from human translators. These systems are trained on hundreds of millions of sentences. The underlying Transformer algorithm is able to extract deep relationships between words. For example, a rule-based translation system that analyzes the grammatical structure of sentences could translate "The dog crossed the road because it was hungry" as "Der Hund kreuzte die Straße, weil er hungrig war" or "Der Hund kreuzte die Straße, weil sie hungrig war". The second translation means that the street was hungry, which is obviously not what is meant. Neural network-based systems will "learn" that "hungry" is much more closely associated with "dog" than with "street".
In technical documents, especially patents, the situation is often more complicated. For example, in a sentence starting with "A micromechanical device having a first circuit portion connected between two lines comprising a first semiconductor material having a depleted zone with a plurality of quantum dots...", basically anything can refer to anything. The translator will have to carefully study what is going on, consult the drawings of the patent, look up other parts of the patent to understand the specific meanings... A neural network based system might even be able to translate a nicely sounding sentence, but it might not extract the meaning correctly.
This is why almost all patent translators are engineers or physicists. The real task of patent translation is to understand the meaning of the disclosed matter.
Dictation greatly increases the productivity of experienced translators. Skilled translators essentially 'read down' the original text, rarely taking their eyes off the original document. The accuracy of state-of-the-art speech recognition systems such as Dragon Naturally Speaking is very high for general texts. However, in the context of patent documents, the vocabulary is so extensive that it is impossible to adapt the vocabulary to the extent that it would make sense to edit the recognised text directly. Most patent translators work with a transcriptionist who works from the audio files of the dictation. Even if parts of the dictation are incorrectly recognised, speech recognition generally increases the productivity of patent translators because the recognised text helps the translator to keep track of the dictation, particularly in the case of very long and complicated sentences. It is also helpful to be able to refer back to previously translated segments when translating a sentence that is similar to one translated a few hours or days earlier. The translator may not remember exactly how the segment was translated and can look it up using the speech-recognised text.
Translation memory systems such as SDL Trados are widely used by translators. They help to identify pre-translated sentences that are similar to the sentences currently being translated and help to maintain consistent terminology. Translation memory systems are more suitable for translators who type their own translations. Dictating translators usually don't use them because they don't integrate very well with dictation and speech recognition systems.
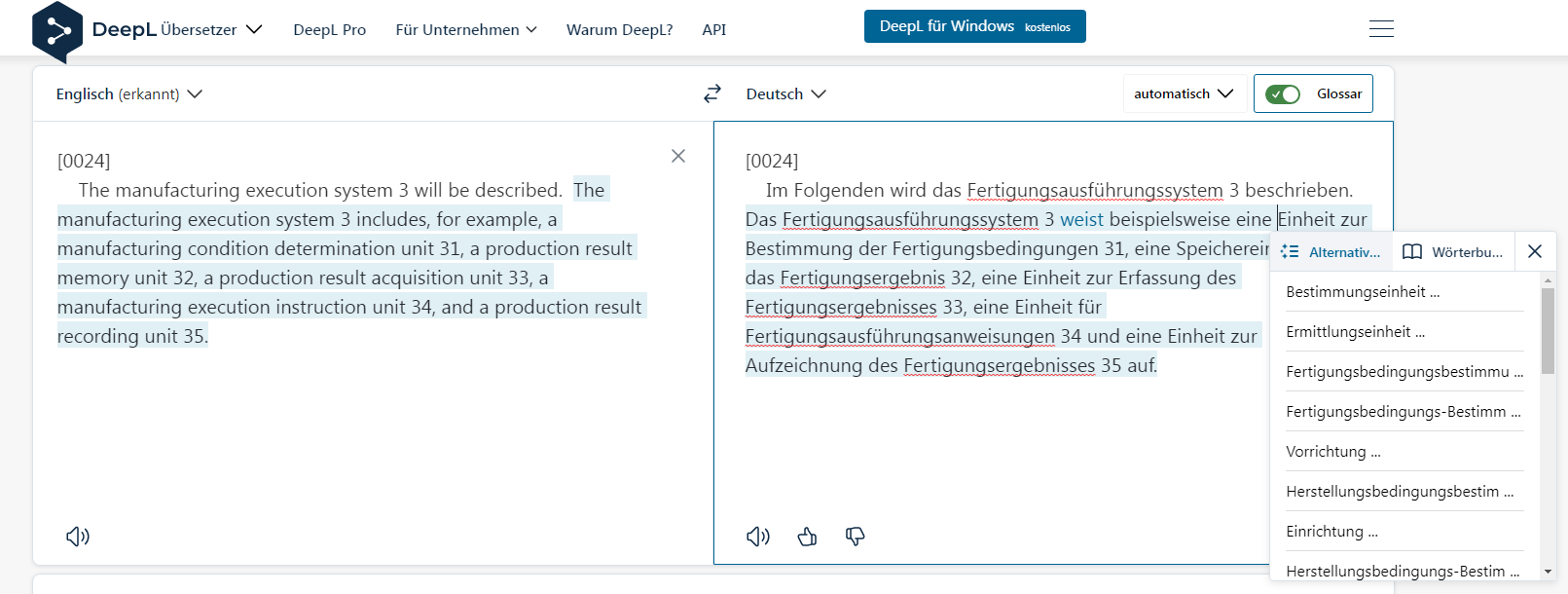
Recent versions of state-of-the-art commercial neural network-based translation systems allow the use of glossaries to maintain consistent terminology. The system suggests alternative translations for terms as the cursor hovers over the translated text in the interactive window, and adjusts the translation of the rest of the sentence if a term is changed. This feature, combined with the already impressive translation quality, makes these systems tempting even for experienced translators. The following figure shows an example of such a commercial system.
Although such an interactive system may be tempting for newcomers to the translation business, for experienced translators the benefits of translating using a dictation system over editing and writing are still significant. The workflow of reading the original sentence, checking the translation provided by the translation system, making adjustments and possibly making corrections is more time-consuming than directly reading the source text and translating it via dictation. A major problem that has been found with post-editing translations from these systems is that the translations almost always sound good, even though they may be at least partially incorrect. These mistranslations are sometimes highly suggestive, and the translator has to examine the original sentence and the translated sentence very carefully to find the mistranslated sections.
The motivation for the system described here was to bring many of the benefits of terminology management systems, machine translation systems and translation memories into the speech recognition environment used by a dictating translator. Particularly useful features for a dictating translator that have been implemented in the present system are
1) Terminology management
2) Identification of pre-translated sentences similar to the presently translated sentence
3) Automatic translation of sentences with a high degree of similarity to a pre-translated sentence
4) Automatic completion of partially translated sentences in order to speed up dictation
5) A state-of-the art compound word splitter for German
It should be noted that previous systems addressing the above points 1) and 2) developed under the supervision of Dr. Witte starting in 2003 received contributions from
Gerson Bridi, Universidade Federal de Santa Catarina, Florianopolis, Brasil
Carlos Newmar, Universidade Federal de Santa Catarina, Florianopolis (now Rio de Janeiro), Brasil, and
Christoph Szczekalla, Aachen, Germany.
The present system was developed from scratch by Dr Axel Witte with a view to implementing neural networks. Although none of the source code of the above mentioned collaborators was used in the present system, many ideas of these former collaborators influenced the present system. As this previous system was used for many years and optimized for Dr. Axel Witte's work, it paved the way for the current framework.
Prof. Dr. Johann Haller, Department of Language Science and Technology, University of Saarbrücken, Germany, contributed valuable linguistic insights.
The previous systems were based on deterministic, algorithmic methods. The present system, in addition to linguistic knowledge, uses specially designed neural networks with greatly extended capabilities, especially in connection with points 3) and 4) above. In particular, it was found that an efficient compound word splitter for German is crucial for a well-performing system in the field of patent translation, where large German compound words are ubiquitous. As part of this work, a state-of-the-art German compound word splitter was developed.
The following paragraphs describe the particularities of the implementation of these features in the present system:
1) Terminology management
In patent translations the consistent use of terminology is very important. Patent documents may have many thousand words and frequently even tens or hundreds of thousand words. The translation of complicated technical terms is not always obvious. Frequently, many translations are possible.
For example in the case of
"The manufacturing execution system 3 includes, for example, a manufacturing condition determination unit 31, a production result memory unit 32, a production result acquisition unit 33, a manufacturing execution instruction unit 34, and a production result recording unit 35."
the term " production result acquisition unit" could be translated as
- Einheit zur Erfassung eines Herstellungsergebnisses
- Herstellungsergebnis-Erfassungseinheit
- Fertigungsergebnis-Erfassungseinheit
- Einheit zur Erfassung eines Fertigungsergebnisses etc.
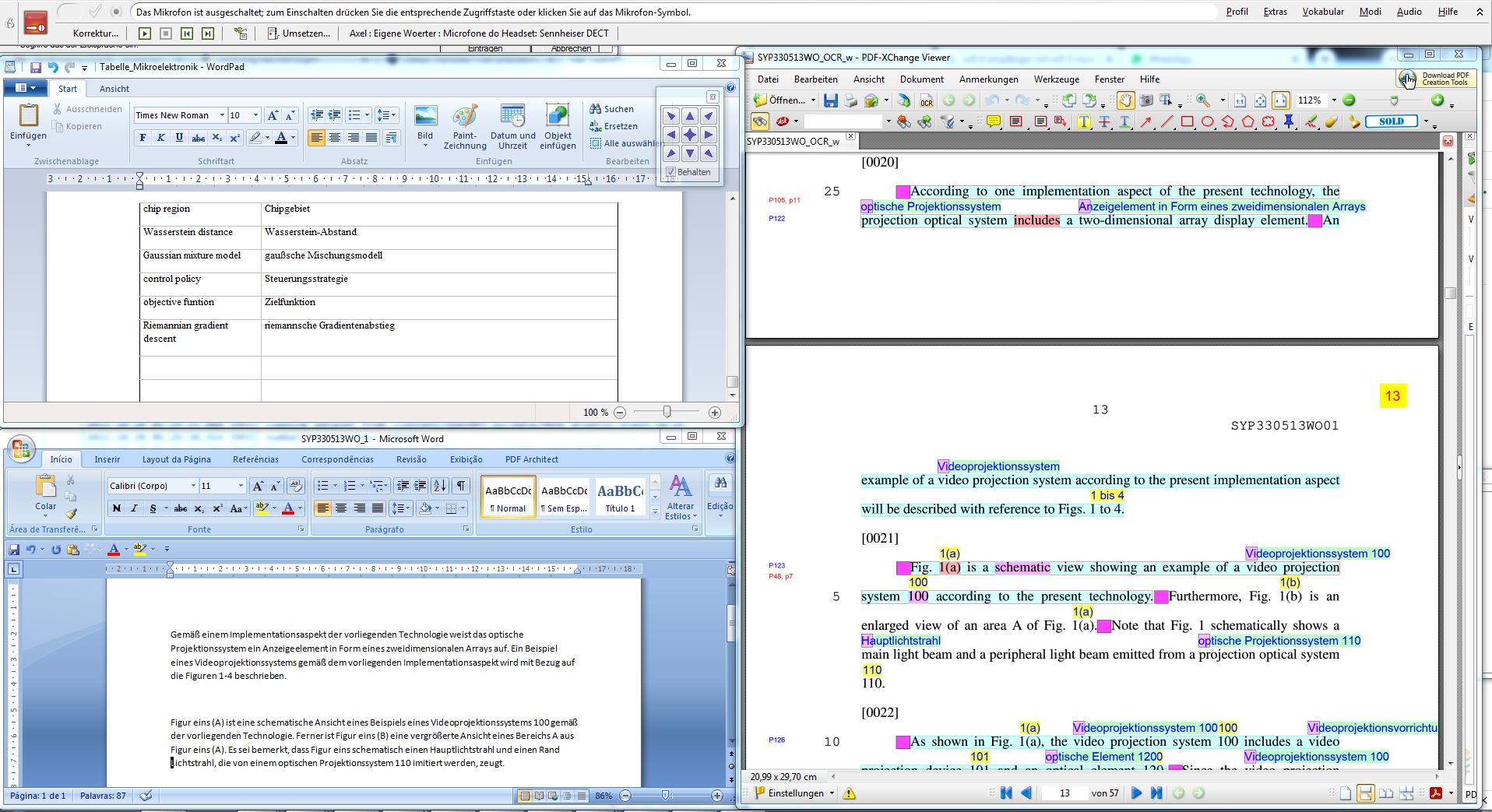
The term might appear on page 7 and on page 89, for example, and the translator might not immediately remember which particular translation was used before. Therefore, it is very convenient to see the translated terms directly in the translation document. The following figure shows the user interface for translation developed in conjunction with the present system:
The translation of the document shown in the right part of the screen appears in the lower right window (speech-recognised with Dragon NaturallySpeaking 15). The terminology used for the document is displayed in the upper right window. New terms can be added here. They can be added to the translation document in the right pane at any time by clicking "Eintragen" in the top left of the screen::
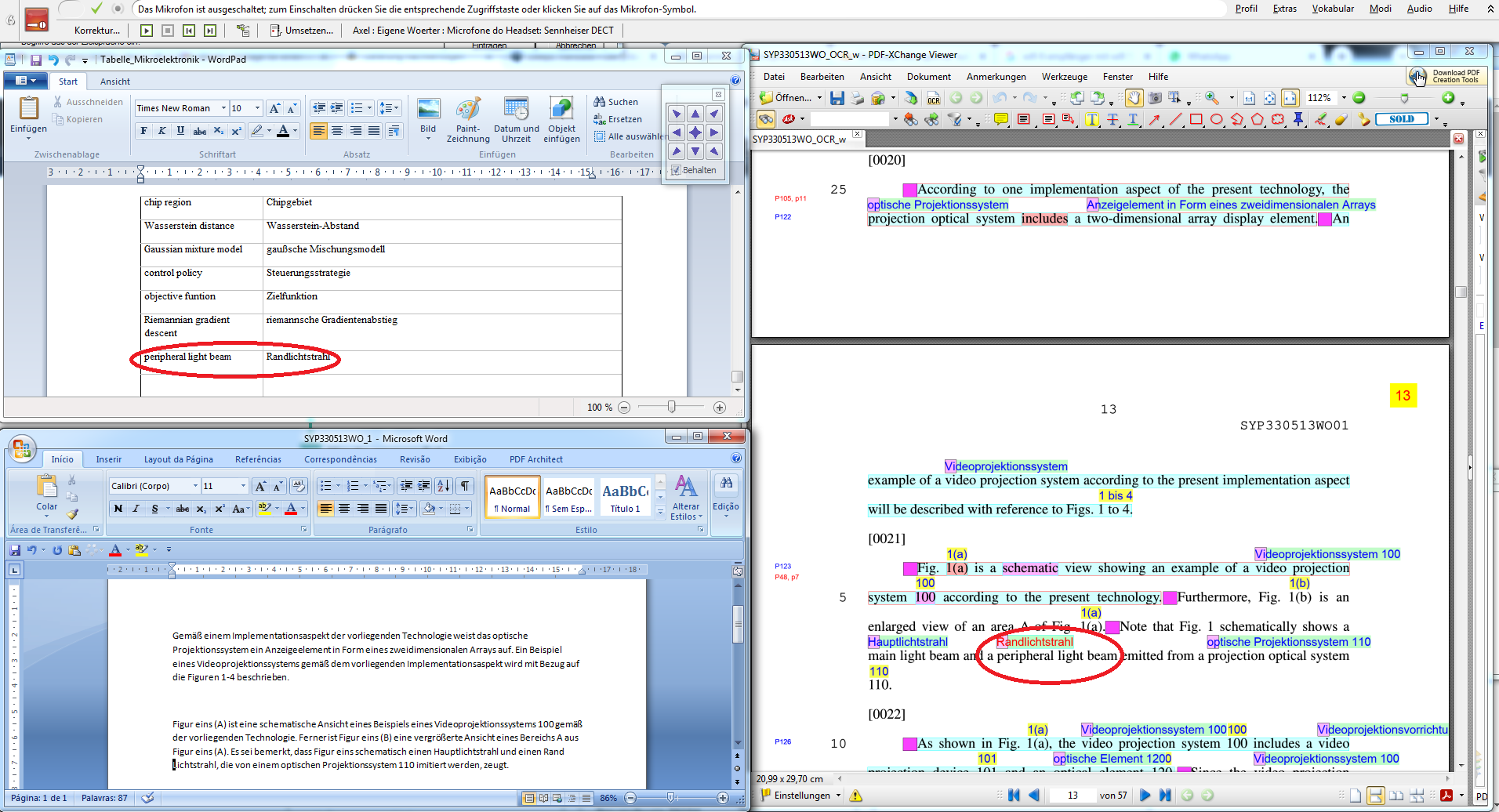
If the term "peripheral light beam" with the corresponding translation "Randlichtstrahl" is included into the terminology list, for example, a few seconds after clicking on "Eintragen", the following screen appears:
Note that the term "Randlichtstrahl" appears in red letters on the right-hand side of the screen. The red letters indicate that this particular position is the first in the document where "peripheral light beam", the term corresponding to "Randlichtstrahl", appears in the present document, which is helpful in determining whether the definite or the indefinite article should be used.
2) Identification of pre-translated sentences similar to the presently translated sentence
Technical documents and patent documents in particular often have a high degree of similarity between sentences. In many cases, sentences describing different embodiments are very similar and in many cases identical, except for different reference signs. We have developed methods to identify similar sentences in documents. The similarity measures take into account different criteria. Sentences may contain a large number of different words, but if these words are contiguous, there may be only one additional half-sentence. Therefore, the number of permutations required to convert one sentence into the other is taken into account. If two sentences differ only in reference characters, there is essentially no additional translation work to be done. Therefore, reference characters are given a low weight when measuring differences. In addition, words such as "first", "second", etc. if they differ between two sentences, essentially don't add much translation work, as they can simply be transferred word for word from one sentence to the other.
The criteria have been adapted over time to best suit our needs.
Consider the following example:
The two sentences marked in red have a high degree of similarity. Light blue markings indicate equal sections, reddish markings indicate alterations, green marking in front of a word indicate that a word or a sequence of words is missing and pink parts indicate added sections.
The characters P874, p59 on the left side of the second sentence indicate that this sentence is similar to sentence P874 on page 59.
Similar sentences can also be identified in a set of documents. A reference document is compared to a number of documents. Similar sentences between the reference document and the number of documents are indicated. The left column in the following diagram shows the documents in the set and "Anzahl ähnlicher Sätze" denotes the number of similar sentences between the respective documents and the reference documents:
For documents in which the number of similar sentences exceeds a predetermined threshold the similar sentences are marked as described above.
3) Automatic translation of sentences with a high degree of similarity to a pre-translated sentence
If a sentence is to be translated that is similar to a sentence that has already been translated, the sentence to be translated should be translated as closely as possible to the sentence that has already been translated. If the previously translated sentence was translated a few hours or days ago, the translator may not remember exactly how the sentence was translated. He will then have to look it up in the speech-recognised text, which is always a distraction and associated with time loss. If the new sentence only differs in a reference number, for example, the transformation between the previous sentence and the one being translated is trivial. If the translator has a good transcriber, the translator can simply tell the transcriber to make the change. However, even a single different word between the two original sentences can lead to considerable differences in the translated German sentences. Consider the sentence "The transistor is new." and the similar sentence "Further, the transistor is new." . A translation of the first sentence would be "Der Transistor ist neu. "
A valid translation of the second sentence would be "Ferner ist der Transistor neu.", i.e. the structure of the sentence in the German translation differs considerably from "Der Transistor ist neu" because the position of the verb "ist" is also altered.
The two sentences
mentioned in the section "Identifying Similar Sentences in Documents" only differ in that in the second sentence "the server 1420 may load" is added and "may be loaded for the client 1410" is deleted. However, the German translations will differ to a higher degree than the original sentences because the German passive form (translation of "may be loaded") is syntactically more complicated than the English passive form.
A good translation for the first sentence would be:
"Gemäß einer Ausführungsform kann eine Texturbefehlsliste für den Client 1410 zur Boot-Zeit geladen werden, welche Befehlskennungen von Texturdaten aufweisenden Grafikverarbeitungsbefehlen enthalten kann."
A good translation for the second sentence (given the first sentence and its translation) would be:
"Gemäß einer Ausführungsform kann der Server 1420 zur Boot-Zeit eine Texturbefehlsliste laden, welche Befehlskennungen von Texturdaten aufweisenden Grafikverarbeitungsbefehlen enthalten kann."
The present system was developed in order to deliver translations of similar sentences. The system was designed to reproduce the terminology and structure of the already translated sentence to a high degree. Sentences with a similarity degree as in the previous example
are translated correctly with confidence.
Conveniently, the original sentences, modified sentences, differences between original and modified sentences,
translations of the original sentences, translations of the modified sentences generated by the system and differences of the translations of the original sentences and modified sentences are output in the form of a Word file showing the respective sentences and the differences between them:
23
Ursprünglicher Satz
Even when the multi-focusing functions , due to reflection loss of the laser beam at the interface between the medium outside the capillary and the capillary and due to reflection loss of the laser beam at the interface between the medium inside the capillary and the capillary , the intensity thereof attenuates as the laser beam travels in the capillary array , and the obtained fluorescence intensity also attenuates accordingly .
Modifizierter Satz
Even when the multiple laser-beam focusing functions , due to reflection losses of the laser beam at the interfaces between the medium outside the capillaries and the capillary and due to reflection losses of the laser beam at the interfaces between the medium inside the capillaries and the capillary , the intensity of the laser beam attenuates as the laser beam travels in the capillary array , and intensity of fluorescence obtained from the capillaries also attenuates accordingly .
Modifizierter Satz mit Unterschieden gegenüber Originalsatz
Even when the multiple laser-beam focusing multi-focusing functions , due to reflection losses loss of the laser beam at the interfaces interface between the medium outside the capillaries capillary and the capillary and due to reflection losses loss of the laser beam at the interfaces interface between the medium inside the capillaries capillary and the capillary , the intensity of the laser beam thereof attenuates as the laser beam travels in the capillary array , and intensity of fluorescence obtained from the capillaries obtained fluorescence intensity also attenuates accordingly .
Übersetzung des ursprünglichen Satzes
Selbst wenn die Mehrfachfokussierung funktioniert, wird infolge des Reflexionsverlusts des Laserstrahls an der Grenzfläche zwischen dem Medium außerhalb der Kapillare und der Kapillare und infolge des Reflexionsverlusts des Laserstrahls an der Grenzfläche zwischen dem Medium innerhalb der Kapillare und der Kapillare die Intensität des Laserstrahls abgeschwächt, während er sich im Kapillarfeld fortpflanzt, und die erhaltene Fluoreszenzintensität wird entsprechend auch abgeschwächt.
Übersetzung des modifizierten Satzes
Selbst wenn die Mehrfachlaserstrahlfokussierung funktioniert, wird infolge von Reflexionsverlusten des Laserstrahls an den Grenzflächen zwischen dem Medium außerhalb der Kapillaren und der Kapillare und infolge von Reflexionsverlusten des Laserstrahls an den Grenzflächen zwischen dem Medium innerhalb der Kapillaren und der Kapillare die Intensität des Laserstrahls abgeschwächt, während er sich im Kapillarfeld fortpflanzt, und die Intensität der aus den Kapillaren erhaltenen Fluoreszenz wird entsprechend auch abgeschwächt.
Übersetzung modifizierter Satz mit Unterschieden gegenüber Originalsatz
Selbst wenn die Mehrfachlaserstrahlfokussierung Mehrfachfokussierung funktioniert , wird infolge von Reflexionsverlusten des Reflexionsverlusts des Laserstrahls an den Grenzflächen der Grenzfläche zwischen dem Medium außerhalb der Kapillaren Kapillare und der Kapillare und infolge von Reflexionsverlusten des Reflexionsverlusts des Laserstrahls an den Grenzflächen der Grenzfläche zwischen dem Medium innerhalb der Kapillaren Kapillare und der Kapillare die Intensität des Laserstrahls abgeschwächt , während er sich im Kapillarfeld fortpflanzt , und die Intensität der aus den Kapillaren erhaltenen Fluoreszenz erhaltene Fluoreszenzintensität wird entsprechend auch abgeschwächt .
A dictionary can be set. For example, if "multiple laser-beam focusing --- Mehrfachlaserstrahlfokussierung" is in the dictionary, the translated sentence will have the form presented above. In the case of "multiple laser-beam focusing --- Mehrfach-Laserstrahlfokussierung", the above translation of the modified sentence " Übersetzung des modifizierten Satzes" would be:
Übersetzung des modifizierten Satzes
"Selbst wenn die Mehrfach-Laserstrahlfokussierung funktioniert, wird infolge von Reflexionsverlusten des Laserstrahls an den Grenzflächen zwischen dem Medium außerhalb der Kapillaren und der Kapillare und infolge von Reflexionsverlusten des Laserstrahls an den Grenzflächen zwischen dem Medium innerhalb der Kapillaren und der Kapillare die Intensität des Laserstrahls abgeschwächt, während er sich im Kapillarfeld fortpflanzt, und die Intensität der aus den Kapillaren erhaltenen Fluoreszenz wird entsprechend auch abgeschwächt."
The Neural Network works best if the degree of similarity between the original sentence and the modified sentence is higher than about 80 percent. It is not a full translation system meaning that it is not designed to translate a modified sentence if the original sentence is basically unrelated to it.
4) Automatic completion of partially translated sentences
As mentioned above, experienced translators basically "read down" the translation, in particular of well-written and not to complicated text sections. Talking for hours in a row generally gets rather tiring and inevitably leads to lower concentration and output over time. Moreover, it simply takes time to read the translation of sentences that are obvious to the translator. In the case of such sentences, the translators productivity is basically limited by the speed of talking. The following paragraph shows an example of such a lengthy but simply structured sentence:
A possible translation of this sentence is:
"Das Trainings- und Optimierungssystem 4 weist beispielsweise die Sensorinformations-Aufzeichnungseinheit 401, eine Merkmalsextraktionseinheit 402, eine Merkmalsdatenbank 403, eine Dimensionsverringerungsmodell-Trainingseinheit 404, eine Trainiertes-Dimensionsverringerungsmodell-Speichereinheit 405, eine Trainiertes-Dimensionsverringerungsmodell-Zwischenspeichereinheit 406, die Prozessdaten-Aufzeichnungseinheit 407, eine Prozessdatenbank 408, eine Dimensionsverringerungsmodell-Leseeinheit 409, eine Dimensionsverringerungs-Ausführungseinheit 410, eine Verbindungseinheit 411, die Trainingsdatenbank 412, eine Regressionsmodell-Trainingseinheit 413, eine Regressionsmodell-Speichereinheit 414, eine Trainiertes-Modell-Zwischenspeichereinheit 415, eine Regressionsmodell-Leseeinheit 416 und die Einheit 417 zur Erzeugung optimaler Bedingungen auf."
Because the sentence is basically an enumeration of items the translations of which are in the dictionary, in principle, the translator doesn´t have to contribute very much information. Instead of dictating the whole sentence, all necessary information is in principle contained in the partial sequence: "Das ˽ weist beispielsweise ˽". It takes a considerable time to dictate the entire translated sentence. The system developed in this context is able to complete such sentences on the basis of a given sentence fragment such as "Das ˽ weist beispielsweise ˽" which is much faster to dictate and leads to much less fatigue on the side of the translator.
The symbol "˽" is a placeholder for indicating a missing part. It only serves for illustrative purposes. Nothing is dictated here. The present system is designed to complete such sentence fragments.
Of course, the more information that is provided in the dictated part, the fewer degrees of freedom the system has to generate the complete translated sentence. It will have been noticed that there is a highlighted field at the beginning of each sentence and that the words which are part of the dictionary are highlighted in color. The highlighting colors uniquely code the words in the dictionary. Clicking on the small first part of the highlighting of words in the dictionary selects the base form of the word. By clicking on the second, larger part of the highlighting, the system selects the additional information for these words, which may later need to be inflected. The small pink marks at the beginning of the sentences are also color coded. Each sentence is associated with a specific color. The translator occasionally has to click onto these fields in order to provide orientation for the system about the position at which the translation occurs at a specific time. Clicking on highlighted words is much faster than dictating, especially for long words. The system records the clicked words, including their position in the dictation, and uses a text-to-speech module to embed them in the dictated audio sent to the transcriber..
5) A state-of-the-art compound word splitter for German
Designing a neural network for the tasks described above for German is complicated by a peculiarity of the German language: Nouns can, in principle, be compounded indefinitely. Words like the above "Mehrfachlaserstrahlfokussierung" will only appear a few times in the entire patent literature. As a matter of fact, of the about 4.5 million nouns present in the entirety of patents filed in the German language over the last 25 years, almost half appear less than twice.
The neural networks devised for the above tasks learn from relationships between words. The problem is that computers don´t know anything about words. Thus, every "word" is finally represented by a number. However, if words only appear a few times in the entire material on which the neural network "learns", there will be not much context for these words. However, e.g. the word "Mehrfachlaserstrahlfokussierung" is a concatenation of
"Mehrfach", "Laserstrahl" and "Fokussierung", words which are much less infrequent than "Mehrfachlaserstrahlfokussierung". Thus, splitting compound words into much more frequent components is the standard way of alleviating the problem of infrequent compound words.
Current state-of-the-art language models such as GPT-4 or Google BART use statistically based splitters such as BytePairEncoding (bpe) or Sentencepiece. They work rather well with many languages including English, are fast to apply and have the advantage that a fixed vocabulary size can be defined. However, a lot of information is lost in the case of complex compound words in German. For companies like Google and Microsoft this might not be so much of a problem because they have large resources and can train models on hundreds of millions of sentences. We do not have such resources and have to make good use of our data. In order to illustrate the problems with statistically based splitters, the following example of BypePairEncoding for German with a vocabulary fixed to 100000 words will be considered:
bpemb_de_100k.encode("zuleitungsdraht") = ['_zul', 'eitungs', 'draht']
The last component "draht" actually makes sense. The rest hast nothing to do with the meaning of the word "Zuleitungsdraht".
As another example the compound noun "Neutralzuleitungsdraht" which is a compound of "Neutral" and the previous "Zuleitungsdraht" is considered:
bpemb_de_100k.encode("neutralzuleitungsdraht") = ['_neutr', 'alz', 'ul', 'eitungs', 'draht']
Again, the last component "draht" makes sense, however, the rest does not. In particular in ("zuleitungsdraht") ['_zul', 'eitungs'] could be associated with "Zuleitung". In the split of "Neutralzuleitungsdraht, the first letter of "Zuleitung" was attributed to the component "alz" instead of "zul" in the case of "Zuleitungsdraht".
This means that except for "Draht", all connections between "Neutralzuleitungsdraht" and "Zuleitungsdraht" are lost in the split.
For the present framework a system for splitting such German compound words was designed. The goal was to extract a maximum of information from compound words. At first glance, this seems to be an easy task. One could come up with the idea of simply identifying the partial nouns making up the compound noun. However, compound nouns can not only have components based on nouns but also on adjectives, verbs etc.. In the compound noun "Schleifscheibe", for example, the "Schleif" doesn´t even exist as an isolated word (it derives from the verb "schleifen". The German "Fugen-s" in words like "Flexionsform" complicates matters even more. In many cases, words in which another noun appears have nothing to do with these nouns. For example "Vorrichtung" has nothing to do with "Richtung" and "Kombination" has nothing to do with either "Nation" or "Ion".
We designed a compound word splitter based on a especially designed neural network "learning" the German grammar which outperforms all known compound word splitters for the German language.
The following list shows a few examples of compound splits generated by the present system:
verbrennungsmotorkraftstoffdurchsatz,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'durchsatz']"
verbrennungsmotorkraftstoffeffizienz,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'effizienz']"
verbrennungsmotorkraftstoffeinspritzmenge,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'einspritz', 'menge']"
verbrennungsmotorkraftstoffeinspritzung,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'ein', 'spritz', 'ung']"
verbrennungsmotorkraftstoffeinspritzvorrichtungen,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'einspritz', 'vorricht', 'ung', 'en']"
verbrennungsmotorkraftstofffüllmenge,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'füll', 'menge']"
verbrennungsmotorkraftstoffinjektoren,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'injektor', 'en']"
verbrennungsmotorkraftstoffpumpe,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'pumpe']"
verbrennungsmotorkraftstoffstrom,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'strom']"
verbrennungsmotorkraftstoffstroms,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'strom', 's']"
verbrennungsmotorkraftstoffsystem,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'system']"
verbrennungsmotorkraftstoffsystems,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'system', 's']"
verbrennungsmotorkraftstoffverbrauch,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'verbrauch']"
verbrennungsmotorkraftstoffverbrauchs,"['verbrenn', 'ung', 's', 'motor', 'kraftstoff', 'verbrauch', 's']"
It was found that this compound word splitter considerably increases the performance in particular related to the above tasks 3) and 4).